Head of Data Analytics & Services

Das folgende Gespräch führte unser schwedischer Kollege Fredrik Lannsjö mit Andreas Döring, der mit seinem Team aufgrund der Bedeutung von Daten und der strategischen Fokussierung auf biometrische Produkte, Datenanalyse als neuen Kundenservice aufgebaut hat. Wie schon in der Risiko- und Leistungsprüfung profitieren unsere Kunden und Partner auch im Bereich der statistischen Analyse von unserem Wissen und unserer Erfahrung.
FL: Versicherer erkennen zunehmend den Nutzen ihrer Daten zur Verbesserung ihrer Geschäftsentscheidungen. Was genau bietet SCOR im Bereich der Datenanalyse an?
AD: SCOR unterstützt Versicherer weltweit dabei, ihre Daten besser zu nutzen. Dies beginnt mit der strukturierten Bereitstellung unstrukturierter Daten durch Text Mining und andere NLP-Techniken (Nature Language Processing) und der Entwicklung von Lösungen für die versicherungsspezifische optische Schrifterkennung (OCR) und Informationsextraktion, die in einem breiten Spektrum von Kontexten anwendbar ist. Auf der Grundlage solcher und anderer bereits strukturierter Daten unterstützen wir unsere Kunden dann bei der Analyse dieser Daten durch Anwendung verschiedener Modellierungstechniken. Für den speziellen Fall von Lebensversicherungsportfolio-Daten bieten wir aktuarielle Analysen an, um den Geschäftsverlauf besser zu verstehen und gegebenenfalls geeignetes Optimierungspotenzial zu identifizieren.
FL: Worin siehst Du unsere besonderen Stärken als Rückversicherer?
AD: Fortschrittliche Technologien allein mögen genaue Modelle erlauben, jedoch mit der Gefahr ohne praktischen Nutzen zu bleiben, wenn die Gegebenheiten der Branche nicht schon von Beginn an Berücksichtigung finden. Als Rückversicherer verstehen wir, anders als andere Anbieter von Datenlösungen, die Probleme der Versicherer in ihren verschiedenen Geschäftsbereichen und können in Kombination mit unserer Expertise im Datenbereich dann praxisnahe Lösungen anbieten.
Entsprechend diesem speziellen Ansatz sehen wir gemeinsame Datenanalyseprojekte als eine Gelegenheit, die Interaktion mit unseren Kunden zu vertiefen und letztlich das Geschäft auszubauen.
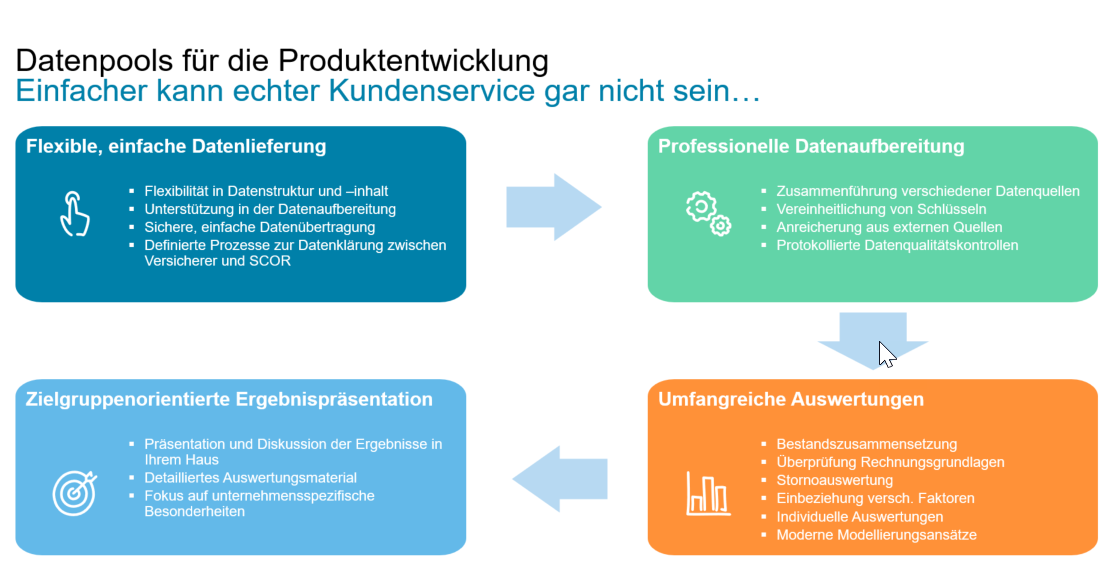
FL: Benchmarking-Pools von Rückversicherern gibt es in Deutschland schon seit einigen Jahren. Welchen besonderen Ansatz verfolgt SCOR?
AD: Wir legen Wert darauf, den Aufwand für den Kunden möglichst gering zu halten, indem wir bei den zur Verfügung gestellten Datenstandards flexibel sind. Gleichzeitig konzentrieren wir uns auf individuelle Kundenbetreuung und kundenorientierte Lösungen hinsichtlich der Frage, welche Verbesserungsmöglichkeiten sich aus den Ergebnissen und Datenqualitätsberichten ergeben können. Wir haben durchweg sehr positives Feedback für unsere Herangehensweise und die daraus gewonnenen Erkenntnisse erhalten, die durch die Anreicherung der Daten mit externen Statistiken, die Verwendung innovativer visueller Darstellungen oder anderer Techniken generiert werden. In Märkten oder Anwendungsfällen, in denen es keine Datenstandards gibt, schätzen die Kunden unsere Unterstützung bei der Datenextraktion oder -strukturierung, wobei wir in Einzelfällen, nach Vereinbarung, sogar per Fernzugriff auf Kundensystemen arbeiten.
FL: Kannst Du Beispiele für Erkenntnisse nennen, die Du mit Kunden besprochen hast?
AD: Bei der Ergebnispräsentation priorisieren unsere Kunden häufig das Thema Verbesserung der Datenqualität. Für Außenstehende ist es schwer vorstellbar, wie herausfordernd es für Aktuare in der Lebensversicherung ist, die „richtigen" Informationen aus Systemen zu extrahieren, die aussagekräftige Portfolioanalysen ermöglichen. Unser Bestreben ist, anhand der gewonnenen Daten valide Ergebnisse zu liefern. Die Erkenntnisse und die von SCOR zur Bereinigung der Daten durchgeführten Maßnahmen nutzen Versicherer dann auch zur Verbesserung ihrer internen Prozesse.
Darüber hinaus ist für die meisten deutschen Versicherer auch die Analyse des Berufsunfähigkeitsgeschäfts mit Schülern und Studierenden von Interesse, welches sie in den letzten Jahren verstärkt in ihr Portfolio aufgenommen haben. Zu Beginn unserer Analysen waren einzelne Versicherer davon überzeugt, dass es sich um eine Besonderheit in ihrem Portfolio handelte. Unsere Vergleiche zeigten jedoch, dass das BU-Geschäft für Schülerinnen und Studierende marktweit eine wesentliche Quelle für Neugeschäft ist. Besonders interessant finden die Teilnehmenden unserer Portfolioanalysen aus der Produktentwicklung die Diskussionen über die unterschiedlichen Annahmemöglichkeiten verschiedener Zielgruppen am Markt sowie die Sicht von SCOR.
Ganz allgemein profitieren die meisten Versicherer von den Gesprächen und Analysen, die sich auf ihre Zielgruppe beziehen, seien es einkommensstarke Personen mit Hochschulabschluss oder Meisterprüfung im Handwerk oder, wie oben erwähnt, Studierende.
FL: Wendet ihr bei diesen Analysen auch Techniken des maschinellen Lernens (ML) an?
AD: Ja, natürlich. Betrachtet man die aktuellen Anforderungen an aktuarielle Studien, so stellt die hohe Dimensionalität der Daten in Verbindung mit dem begrenzt verfügbaren Volumen eine Herausforderung dar. Man kann sich überlegen, wie viele beobachtbare Fälle man in den verschiedenen Kategorien braucht, um eine verlässliche Tafel, differenziert nach Alter, Geschlecht, Raucherstatus, BMI, Familienstand und beruflicher Risikoklasse, zu erstellen. Obwohl eine solch granuläre Preisdifferenzierung aktueller Standard in vielen Märkten ist, wäre dies mit klassischen Methoden, bei denen jede Risikokombinationszelle einzeln betrachtet wird, nicht machbar. Statistische Modelle wie etwa Generalized Additive Models (GAM) ermöglichen es, alle Merkmale gewissermaßen synchron zu berücksichtigen. Herausfordernd bleibt jedoch nach wie vor die hohe Korrelation mit nicht messbaren sozioökonomischen Selektionseffekten.
Darüber hinaus sind ML-Modelle, wie bereits erwähnt, sehr hilfreich und manchmal sogar erforderlich, um zusätzliche Freitextinformationen wie Ausschlussklauseln oder Leistungsbeschreibungen für statistischen Auswertungen zu strukturieren.
FL: Wie wird künstliche Intelligenz (KI) und maschinelles Lernen Deiner Meinung nach die aktuarielle Rolle verändern?
AD: Ich glaube, dass es sich eher um eine schrittweise Veränderung als um eine Revolution handeln wird. Statistik und die daraus gewonnenen Erkenntnisse waren für Aktuarinnen und Aktuare schon immer wichtig. Künstliche Intelligenz ist ein weiteres Hilfsmittel, um mit komplexeren Daten umgehen zu können - aber das bedeutet nicht, dass die Ergebnisse der Modelle einfacher zu verstehen sein werden. Die Modelle tragen zwar dazu bei, die statistischen Schwankungen der Ergebnisse zu beseitigen und potenzielle Muster klarer zu erkennen. Diese Muster können jedoch immer noch sehr komplex sein. Daher werden die entsprechenden Modelle auch selten unverändert verwendet. Manchmal fordern die Aufsichtsbehörden die Versicherer auf, einfache, erklärbare Modelle zu verwenden, beispielsweise um versteckte Diskriminierung zu vermeiden. Zusätzlich fordern Vertriebskanäle häufig nachvollziehbare Preismodelle, die für Kunden einfach zu verstehen sind. Eine gewisse aktuarielle Erfahrung bleibt also erforderlich, um die Komplexität der Modelle auf ein akzeptables Niveau zu senken, aber gleichzeitig genau genug zu bleiben, um nicht anfällig für Antiselektion zu sein.
Eine weitere Veränderung für den aktuariellen Berufsstand wird darin bestehen, dass zumindest grundlegende Kenntnisse über noch komplexere ML-Modelle vorhanden sein müssen, um die Strukturierung und Auswertung neuer, großer Datenquellen wie Bilder, Telematikdatenströme usw. validieren und für die Preisgestaltung nutzen zu können.
FL: Kann man sagen, dass die Auswirkungen der KI auf die gesamte Versicherungsbranche weitreichender sein werden als auf die aktuarielle Rolle?
AD: Das hängt von der Betrachtungsweise ab. Natürlich wirken sich KI-basierte Tools auf weit mehr Bereiche aus als nur auf Produkte und deren Preisgestaltung: in der Kundenkommunikation, beispielsweise, die durch Chatbots oder Sprachassistenz unterstützt wird; in der automatisierten Weiterleitung und Verarbeitung schriftlicher Kundenkommunikation oder die Automatisierung der Schadenbearbeitung usw.
Andererseits ändern diese rein technischen Entwicklungen nichts am Kern des Geschäfts, das auf dem kontinuierlichen finanziellen Versprechen beruht, auf das sich die Versicherten verlassen können.