
Head of Data Analytics & Services

Seit einigen Jahren wertet SCOR intensiv Portfoliodaten zum Mortalitäts- und Invaliditätsrisiko im Auftrag von Lebensversicherern aus, die aus den Vergleichen und Analysen konkrete Ansätze ziehen, wie sie ihre Geschäftsentwicklung verbessern können. Heute möchten wir Sie herzlich zu einer kleinen Zeitreise einladen und Ihnen einen Einblick geben, womit wir uns in den letzten Jahren beschäftigt haben.
Begonnen haben unsere Datenanalysen mit einem kleinen Datenvolumen für einen Pool zu Leistungsbeständen und Auswertungen, insbesondere zur Reaktivierung nach Schadenursache und weiteren Kriterien.
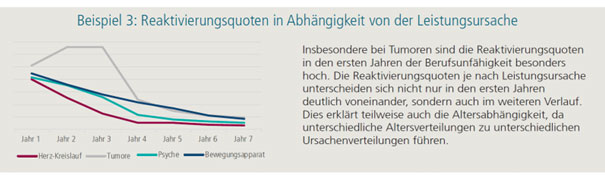
Abbildung 1 - aus dem damaligen Produktflyer
In kürzester Zeit erreichte dieser Pool ein beachtliches Volumen (s. Grafik Entwicklung der Poolvolumina „Invaliditätsleistungen“ auf der nächsten Seite), und es stellte sich heraus, dass Excel und VBA allein keine ausreichenden Analysemittel darstellten.
Im Rahmen einer Re-Fokussierung der Strategie für den deutschen Markt auf biometrische Produkte wurden dann 2016 erstmalig spezialisierte personelle Ressourcen bereitgestellt, um im größeren Umfang solche Portfolioauswertungen auch für aktive BU- sowie Risikolebensversicherungsbestände durchführen zu können.
Um eine weitgehende Automatisierung bei gleichzeitiger Verwaltung perspektivisch großer Datenbestände zu erreichen, haben wir uns damals für die Statistiksoftware SAS als System entschieden. Die Ausführungszeiten unserer Routinen waren erstaunlich, wenn man bedenkt, dass Daten letztlich Zeile für Zeile von der Festplatte gelesen und wieder auf diese geschrieben werden, wodurch meist kein größerer Hauptspeicher erforderlich ist. Gelegentlich waren dazu allerdings optimierende Eingriffe in die Datenverwaltung (Setzen von Indizes) und weitere Routinen (Einsatz von sogenannten Key-Merges) notwendig.
Ein weiterer Vorteil von SAS bestand darin, dass SAS erlaubt, Bezeichnungen und Darstellungen für Datenvariablen und -inhalte in der Darstellung und Analyse unabhängig von ihrer Repräsentation im System zu wählen. Somit wurden beispielsweise deutschsprachige Auswertungen aus einem international angelegten Datenformat erleichtert und wir konnten hohe, teils inhomogene Datengranularitäten einheitlich gruppieren. Beide Anwendungen der sogenannten „Labels“ klassischer Statistik-Systeme wie SAS oder SPSS sind in anderen Programmiersprachen schwierig zu replizieren.
Da in Deutschland bereits seit Jahren verschiedene Benchmarking-Pools existieren, war es für uns von Anfang an wichtig, außergewöhnliche Stärken und Fähigkeiten zu entwickeln, um Ihre Interessen als Kunde in den Fokus zu stellen. Dies gelang entlang zweier Hauptachsen, die für uns immer noch von größter Relevanz sind: Wir gehen dabei in der Auswertung thematisch konsequent und individuell auf Sie ein und reduzieren dabei gleichzeitig Ihren Aufwand auf ein Minimum.
Anders als vergleichbare Pools geben wir Ihnen kein Datenformat vor. Sie können uns die Daten bereitstellen, die Sie schon anderweitig aufbereitet haben - ohne Extraaufwand. Aus unserer Beschäftigung mit den verschiedensten, am Markt verbreiteten Standards und kundenspezifischen Formaten resultiert sowohl eine umfassende Expertise zur automatisierten Verarbeitung verschiedener Formate als auch ein besonderer Fokus auf Datenqualität. In vielen Ergebnisgesprächen mit unseren Kunden wurde der Wert dieser detaillierten Beschäftigung mit den Daten sehr begrüßt, nicht zuletzt da hierdurch auch interne Auswertungen verbessert werden konnten.
Nachdem wir in Produktentwicklungsprojekten mit verschiedenen Erstversicherern die Berufsgruppeneinteilungen beurteilt haben, ist es uns gelungen, sehr gute Werkzeuge zur automatisierten Klassifikation von Berufstiteln zu verwenden. Dabei verwenden wir die gemeinsame Klassifikation der Berufe des Statistischen Bundesamts und der Bundesagentur für Arbeit von 2010, an der sich auch der letzte Berufsschlüsselvorschlag des GDV orientiert. Dies erlaubt uns nicht nur aussagekräftige Vergleiche der Leistungseintritte von Versicherten auf einer einheitlichen Berufsgruppeneinteilung, sondern auch spezialisierte Auswertungen auf der Basis neuerer Berufsforschung, wie in unserem früheren Projekt zur Zukunft der Arbeit.
Letztlich haben wir es durch diesen Ansatz geschafft, einen Pool aufzubauen, der durchaus valide Marktvergleiche zulässt.
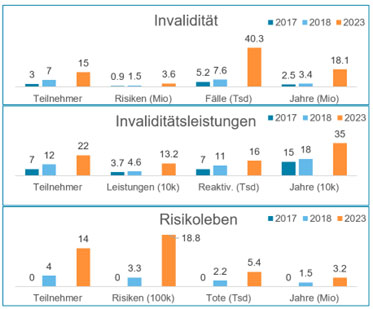
Abbildung 2 Entwicklung der Poolvolumina
Der Wert von Portfolioanalysen ist auch international stärker in den Fokus gerückt. SCOR hat in die Entwicklung eines Systems zur Durchführung von Studien namens APEX investiert, welches wir auch Ihnen als Kunden zur Verfügung stellen.
Kurz nach der Fertigstellung dieses Systems ergab sich ein neuer Zuschnitt der Zuständigkeit unseres Teams und andere Märkte wurden integriert. Im größeren Team waren nicht alle Teammitglieder mit SAS vertraut, und auch nicht alle Produkte unseres Marktbereichs konnten damals in unserem System abgebildet werden. Außerdem wurde offensichtlich, dass in anderen lokalen und zentralen Abteilungen der SCOR, die sich mit der Modellierung und Quantifizierung von biometrischen Risiken befassen, zunehmend R statt SAS verwendet wurde. Somit war es im Sinne der engen Zusammenarbeit naheliegend, dass das gesamte Team einheitlich an einer Neuentwicklung der Importe nach APEX auf der Basis von R arbeiten wird. Unser Ziel war es dabei, die größtmögliche Effizienz bezüglich des Einsatzes von erfahrenen Kolleginnen und Kollegen zu erreichen:
Höhere Automatisierung im Einleseprozess für bekannte Datenformate (insbesondere für Deutschland im Hinblick auf Berufsschlüssel)
Standardisierung kundenspezifischer Datenformate weitgehend ohne Programmierung inkl. Validierungsregeln (Low-Code Ansatz)
Qualitätsberichte auf verschiedenen Detailniveaus
Darüber hinaus sollten Systeme entwickelt werden, um Studienergebnisse des APEX-Systems mehrsprachig ausgeben zu können und Kundenpräsentationen effizient zu unterstützen.
Nach zwei Jahren Arbeit können wir nun mit Stolz sagen, es geschafft und unser erstes MVP (Minimum Viable Product) erstellt zu haben. Der Weg dorthin war allerdings nicht einfach.
Warum musste der Programmcode überhaupt selbst entwickelt werden? Einerseits sollte das Team nach Abschluss der Entwicklung selbst immer in der Lage sein, „unter die Haube“ zu schauen und auch größere Probleme am System selbst zu beheben, wozu eine intensive Beschäftigung mit dem Code unerlässlich ist. Andererseits waren die bisherigen einzelnen Importprojekte gar nicht so systematisch implementiert, wie dies zukünftig der Fall sein sollte, so dass es sich bei der Übertragung der Einzelimporte nicht um eine 1-1 Migration hätte handeln sollen, die ggf. leicht an Externe auszulagern wäre. Und wenn man sich ohnehin schon überlegen muss, was eigentlich genau gewollt ist, kann man es auch gleich dem Computer selbst erklären und anhand der Ergebnisse nachjustieren - oder nicht?
Bei aller Naivität dieses Ansatzes war klar, dass bei einem Projekt von inzwischen ca. 30.000 Zeilen Programmcode, Dokumentation und vielem Weiterem erheblich in Weiterbildung rund um Software-Entwicklung investiert werden musste: Vertiefte Programmierkenntnisse mit R und die tidyverse Paketlandschaft, Versionierung und Synchronisierung von Codes mittels GIT, Projektmanagement mit AzureDevOps, Paketentwicklung in R inklusive unit tests, Dokumentation, agile Methoden und Rollen, nur um einige Bereiche zu nennen.
In unserem jungen Team gab es naturgemäß mehrere Personalwechsel, so dass der Einarbeitungsprozess mehrfach wiederholt werden musste - auf zunehmendem Niveau der Anforderungen. Unser Anspruch an eine ganzheitliche und verständliche Dokumentation rückte dadurch mehr in den Fokus.
Nicht nur die Entwicklung, Verbesserung und Dokumentation der Funktionen, sondern auch die strukturierte und gleichzeitig flexible Arbeitsweise wären ohne Agilität nicht möglich gewesen.
Einerseits war es fantastisch, etwas zu entwickeln, das für neue Datenprojekte zügig eingesetzt und getestet werden konnte, denn die Alternative hätte in einer vollständigen Entwicklung jedes Imports „from scratch“ bestanden. Hier war klar, jede kleine Verbesserung oder Weiterentwicklung des Systems hilft sofort im konkreten Arbeitsprozess, denn es muss nicht vollständig ausgereift sein, bevor es eingesetzt werden kann.
Andererseits ist bei Projekten, die im alten System abgebildet waren, das Gute ein hartnäckiger Feind des Besseren. Es ist besonders schwierig, nicht jede gute Einzellösung im Altsystem im neuen System erst nachzubauen, bevor der Umstieg erfolgen kann. Um ganzheitlich Fortschritt zu erzielen, muss eben auch im Einzelnen ein Rückschritt in Kauf genommen werden.
Als ambitioniertes Ziel haben wir uns regelmäßige Updates unserer aktiven Rückversicherungskunden gesetzt und eine erheblich gesteigerte Frequenz bei allen anderen Teilnehmenden. Es wird ständige Updates zu unserem Benchmarking-Pool und interaktive Dashboards geben, in denen Sie Ihre eigenen Daten testen und noch besser kennenlernen können.
Wir arbeiten kontinuierlich daran, unseren Datenpool zu erweitern. Um unser Angebot neben besserer Marktabdeckung noch attraktiver zu gestalten, werden wir systematisch die Daten mit bisher kaum vorhandenen Informationen etwa zu Ausschlüssen und Vertriebswegen anreichern und somit noch fundiertere Einsichten liefern können.
Wenn Sie bisher noch nicht an unseren Auswertungen teilnehmen und wir Ihr Interesse wecken konnten, oder Sie Fragen an uns haben, sprechen Sie uns gerne jederzeit auf unseren Auswertungsservice an. Wir freuen uns, Sie als Kunden begrüßen zu dürfen.
Und wenn Sie bereits am Pool teilnehmen, freuen wir uns sehr, bald wieder mit Ihnen über Ihr Geschäft zu sprechen!